Defending AI Systems
Recent years have witnessed the great success of deep neural networks (DNNs) in various fields of artificial intelligence (AI) including computer vision, speech, and robot control. Despite their superior performance, DNNs are shown to be vulnerable to adversarial attacks that add, often imperceptible, manipulations to inputs to mislead the models. This poses a huge challenge in security critical applications such as autonomous driving and medicine. We develop principled algorithms for defending AI systems against adversarial attacks. Leveraging the representative power of Generative Adversarial Networks (GANs), we proposed DefenseGAN and InvGAN, which project input images into the generator manifold to remove adversarial perturbations. We continue to develop novel defending algorithms by exploiting manifold information and study the characteristics of adversarial attacks as well as their effects in real-world applications.
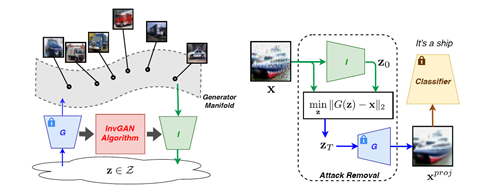
Relevant Publications:
W. Lin, Y. Balaji, P. Samangouei, and R. Chellappa, “Invert and Defend: Model-based Approximate Inversion of Generative Adversarial Networks for Secure Inference”, arXiv preprint arXiv:1911.10291.
P. Samangouei, M. Kabkab and R. Chellappa, “Defense-GAN: Protecting Classifiers Against Adversarial Attacks Using Generative Models”, ICLR, Vancouver, Canada, April 2018.