In this project we aim to extract highly discriminative features from a vehicle image that can naturally facilitate tracking vehicles in the traffic cameras network. Different from prior methods that mainly use license plate to distinguish vehicles, we only rely on visual cues that can be leveraged to re-identify vehicles. The extracted feature vector has much lower dimensionality compared to the original vehicle image and can serve as a representation that maintains critical attributes needed to represent a certain vehicle identity. Attributes such as, vehicle’s model, trim, color, design of head/tail lights, grill, bumpers and wheels. However, this task is challenging due a number of factors; Variations in vehicle’s orientation, illumination and occlusion can significantly deteriorate the quality of feature extraction.
In this project we design Deep Convolutional Neural Network (DCNN) models that not only consider the entire image of the given vehicle, but also assert attention on local regions of vehicles that carry discriminating information regarding the vehicle identity. This particularly alleviates the issue of orientation and occlusion, as these models learn to associate vehicles not only by focusing of the entire vehicle image but also through local regions that might be visible during partial occlusion and in overlapping orientations.
- Adaptive Attention for Vehicle Re-Identification
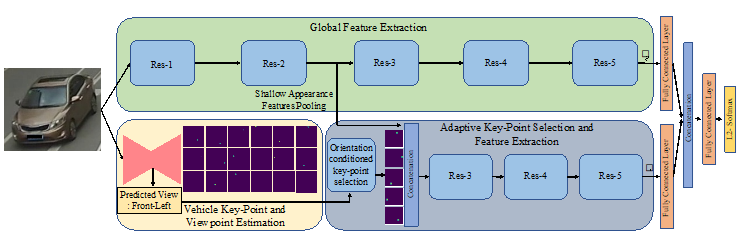
Adaptive Attention for Vehicle Re-Identification (AAVER) localizes the vehicle’s key-points and adaptively selects most prominent key-points based on the vehicle’s orientation. AAVER then extracts both global and local information in the vicinity of selected key-points and encodes it into a single feature vector.
- Khorramshahi, P., Kumar, A., Peri, N., Rambhatla, S.S., Chen, J.C. and Chellappa, R., 2019. A dual-path model with adaptive attention for vehicle re-identification. In Proceedings of the IEEE International Conference on Computer Vision (pp. 6132-6141).
- Khorramshahi, P., Peri, N., Kumar, A., Shah, A., & Chellappa, R. (2019, June). Attention Driven Vehicle Re-identification and Unsupervised Anomaly Detection for Traffic Understanding. In CVPR Workshops (pp. 239-246).
- Self-Supervised Attention for Vehicle Re-Identification
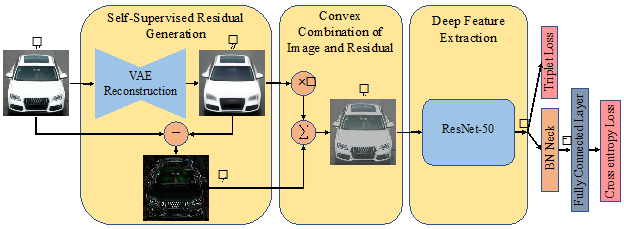
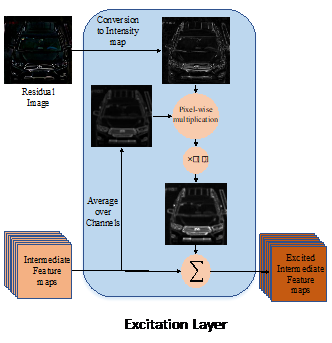
Self-Supervised Attention for Vehicle Re-Identification (SAVER) bypasses the requirment of having extra annotations for vehicles’ key-points and part’s bounding boxes to train specialized detectors. Instead SAVER generates a coarse version of the vehicle image that is free from all the details needed for successful re-identification. Consequently, SAVER produces the sparse residual image that mainly contains the details of the vehicle and is used to enhance and highlight these details in the original image via a trainable convex combination. By adopting latest practices in deep feature extraction, SAVER yields highly discriminating features.
- Khorramshahi, N. Peri, J.C. Chen and R. Chellappa, “The Devil is in the Details: Self-Supervised Attention for Vehicle Re-Identification”, Proccedings of European Conference on Computer Vision, Edinburgh, August 2020.
- Excited Vehicle Re-Identification

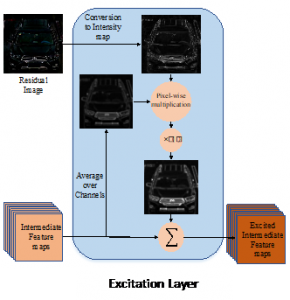
Excited Vehicle Re-Identification (EVER), benefits from the idea of residual generation developed in SAVER to excite the intermediate feature maps within a single path DCNN only during the training phase. This helps the DCNN to learn to better focus on the critical regions of the vehicle that can help in the re-identification process. Since computing residuals and excitation of intermediate feature maps only occur in the training phase, the inference of EVER is super-fast which makes it appealing for real-time applications.
- Peri, N., Khorramshahi, P., Saketh Rambhatla, S., Shenoy, V., Rawat, S., Chen, J. C., & Chellappa, R. (2020). Towards real-time systems for vehicle re-identification, multi-camera tracking, and anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops(pp. 622-623).
Read More